SKAN vs Probabilistic vs SSOT: Why iOS Attribution Is Hard
If you manage mobile app marketing, iOS attribution has become a major challenge. Since Apple's App Tracking Transparency (ATT) changes, deterministic device-level data is now limited, leaving many tools showing conflicting numbers and incomplete signals.
iOS attribution today requires striking a balance between accuracy and privacy. Only about 35%of users opt in to tracking under ATT in 2025, which makes reliable deterministic matches uncommon. At the same time, SKAdNetwork accounts for over40%of iOS attribution, but its delayed and aggregated signals mean marketers don't always get the full picture.
The best approach is to combine privacy-safe SKAN signals, fast but directional probabilistic reads, and a single source of truth (SSOT) to unify data from different tools. This helps you make clearer decisions, optimize more quickly, and avoid wasting your budget.
In this blog, we'll break down SKAN, probabilistic models, and SSOT in simple terms, explain when each is best suited, and provide an easy-to-follow decision table and practical playbook for iOS attribution in 2025.
How ATT Transformed iOS Attribution
Apple introduced the App Tracking Transparency framework with iOS 14.5 in April 2021. This made the Identifier for Advertisers (IDFA) an opt-in feature, blocking access to that identifier unless the user grants permission.
Because most users decline tracking, the marketing ecosystem could no longer rely on deterministic device identifiers for the majority of iOS installs. That shift prompted the industry to adopt privacy-first methods, such as SKAdNetwork (Apple's privacy API), probabilistic models where permitted, and engineering solutions that integrate different data sources into a single source of truth.
The upshot is simple: after April 2021, deterministic ID-based attribution on iOS became rare, and firms had to pick new tools and workflows to measure campaigns.
The Key Attribution Pain Points: Accuracy, Speed & Reporting Consistency
Mobile app marketers face three linked headaches today:
Multiple dashboards: Different vendors report different metrics. SKAdNetwork, attribution partners, ad networks, and internal analytics often each show their own version of installs, events, and conversions. This makes campaign performance hard to compare directly.
Conflicting numbers: Aggregation rules, reporting windows, and privacy-driven data limits create discrepancies. For example, SKAdNetwork reports arrive aggregated and can be delayed, while probabilistic or first-party systems may show near-real-time but less specific counts. The result is that one source may show higher installs, while another shows higher post-install events.
Delayed or partial signals: SKAdNetwork often provides reliable, privacy-safe matches, but with built-in delays and aggregation. Probabilistic methods can be faster, but they carry uncertainty and have legal limitations on iOS. Teams must weigh speed versus trust when making budget and creative decisions.
For mobile app marketers, this means balancing speed, accuracy, and privacy while working with multiple imperfect data views simultaneously. ATT made more than just a flag change on a device. It forced a rebuild of measurement practices. The most practical path for many marketing teams is to combine privacy-first signals (such as SKAdNetwork), carefully applied probabilistic methods where applicable, and a unified data layer or SSOT to reconcile differences and inform decisions.
Also Read: Meta AEM vs SKAN in 2025: Choosing the Right iOS Attribution Stack.
What SKAdNetwork (SKAN) Offers and Its Trade-offs
SKAdNetwork is Apple's privacy-first attribution system, which reports ad-driven installs without using device identifiers. Apple sends anonymized postbacks to ad networks and app owners, rather than sharing user-level IDs.
SKAN 4.0+ Features:
No device IDs / anonymized postbacks: SKAN does not return IDFA or any persistent device ID. Data arrives as aggregated, anonymized postbacks that hide individual identity. This is the core privacy model.
Multiple postbacks (up to three): SKAN 4 can send up to three postbacks for a single install, each tied to a different conversion window (roughly 0–2 days, 3–7 days, and 8–35 days). Each postback can provide progressively later signals about engagement. Postbacks include random timing to protect privacy.
Conversion values and coarse values: Fine-grained conversion values use a 0–63 range (0–63) to encode detailed events or revenue buckets. Coarse values are three-level labels (low/medium/high) that appear when privacy limits prevent a fine value. Use acceptable values for detailed short-term events and coarse values when installing volume or privacy, which means less detail is allowed.
Hierarchical campaign (source) IDs: The old 2-digit campaign ID was replaced by a 4-digit source identifier (up to 10,000 combinations). Ad networks can treat those four digits as hierarchical fields (for example: campaign/creative group/placement/geo) and decide which digits to populate for optimization. Note: Apple may return only 2 or 3 digits if privacy thresholds are not met.
Crowd anonymity thresholds (tiers): Apple assigns an anonymity or "crowd" tier based on the number of installs in the recent window. If a campaign or source has low installs, the postback will omit fine details and reduce the number of returned digits. As install counts rise, more conversion details and more source ID digits become available.
These features trade off some speed and granularity for stronger user privacy. SKAN 4.0+ still gives usable signals for campaign decisions when set up thoughtfully.
Pros
Privacy-compliant attribution that follows Apple rules.
Cleaner, harder-to-fraud signals because Apple signs and controls postbacks.
Longer-term stability: Apple's roadmap centers on SKAN and related privacy tools.
Cons
Timing and delays: usable postbacks may arrive over several days or weeks, rather than instantly.
Lower per-user granularity when privacy thresholds block acceptable values or full source IDs.
Requires campaign scale to unlock full detail; small tests may get limited data.
How to Set Up SKAN Campaigns
The setup approach affects the amount of valuable data SKAN will return. These practical examples focus on schema ideas and a simple runway guideline:
Suggested conversion-value schema ideas (examples)
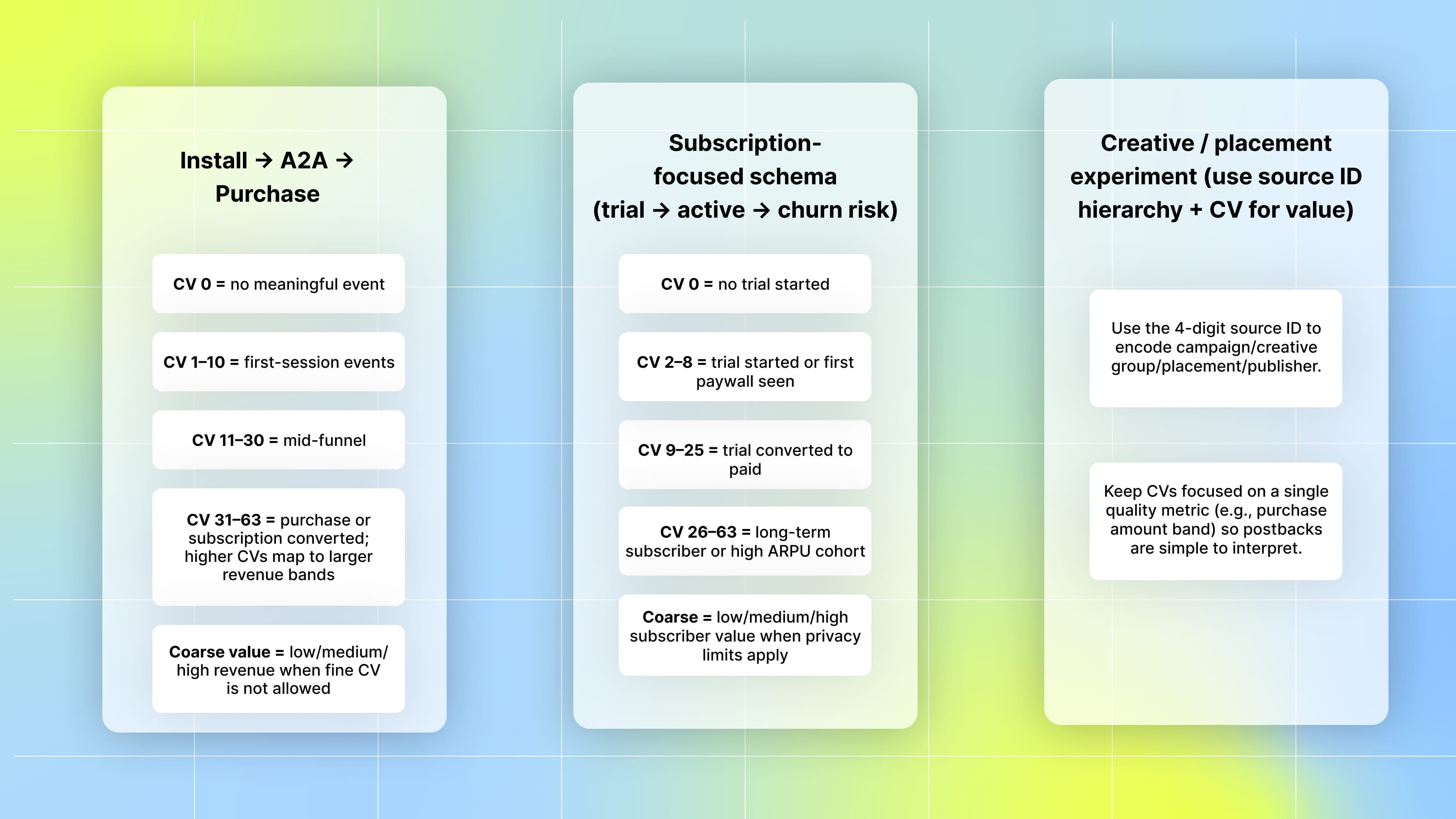
Make conversion-value mappings short and focused. Each example below uses the 0–63 fine value where relevant and illustrates where coarse values are applicable.
Install → A2A (add-to-app) → Purchase (simple funnel).
CV 0 = no meaningful event.
CV 1–10 = first-session events (open, tutorial complete).
CV 11–30 = mid-funnel (A2A or onboarding milestones).
CV 31–63 = purchase or subscription converted; higher CVs map to larger revenue bands.
Coarse value = low/medium/high revenue when fine CV is not allowed.
Subscription-focused schema (trial → active → churn risk).
CV 0 = no trial started.
CV 2–8 = trial started or first paywall seen.
CV 9–25 = trial converted to paid.
CV 26–63 = long-term subscriber or high ARPU cohort.
Coarse = low/medium/high subscriber value when privacy limits apply.
Creative / placement experiment (use source ID hierarchy + CV for value).
Use the 4-digit source ID to encode campaign/creative group/placement/publisher.
Keep CVs focused on a single quality metric (e.g., purchase amount band) so postbacks are simple to interpret.
More events encoded into a single CV mapping increasecomplexity and reduce the number of distinct things that can be tracked. Keep mappings lean and test iteratively.
Suggested budget runway to hit thresholds
For initial tests on iOS in the U.S. market, plan a daily spend within a band that allows a campaign to reach the anonymity thresholds. A commonly practical starting runway is $500–$1,000 per day for a new campaign while learning. This helps the campaign generate enough installs to reveal conversion values and more source-ID digits.
If the app is niche or the creatives are unproven, expect to run longer before clear signals show. Use early probabilistic signals for directional decisions, but rely on SKAN for final budget shifts.
With simple, focused CV schemas and an initial runway large enough to meet privacy thresholds, SKAN can surface meaningful, privacy-safe signals that guide longer-term optimization.
Probabilistic Attribution: Speed with Uncertainty
Probabilistic attribution estimates which ad is likely to drive an install using device signals, such as IP addresses, timestamps, and non-persistent fingerprints, without relying on user-level IDs. It provides fast, directional insights rather than confirmed, device-level data.
The model establishes a statistical match between an ad event (click or view) and an install by comparing signal patterns across multiple events. It assigns a probability to the likelihood that a given ad caused the install, which is used for reporting and short-term optimization.
Benefits
Speed: Models can provide feedback in hours, allowing creative and bid tests to move quickly.
Daily signal: Because it's not waiting on delayed privacy postbacks, probabilistic approaches produce finer day-to-day data for bidding and creative decisions.
Limitations
Modeled, not confirmed: Probabilistic matches are estimates. They can be directionally useful but are not the same as deterministic (device-level) confirmation.
Policy risk: Apple explicitly restricts fingerprinting and methods that link users across apps. That makes probabilistic approaches fragile on iOS if they cross lines Apple defines as tracking. Apple and industry observers have criticized the use of device-fingerprinting techniques.
Requires scale for reliability: Probabilistic models work best with volume. Industry guidance commonly cites thousands of installs before estimates stabilize. Small samples lead to noisy, biased results.
Use Cases Where Probabilistic Helps
Early-stage testing: Fast signals let teams test creatives, audiences, and channels without waiting days for privacy-first postbacks.
Rapid creative optimization: When a campaign requires quick, iterative creative changes, probabilistic feeds can help identify which variants perform better on a day-to-day basis.
Retargeting with ATT consent: If users have opted into ATT (or where consented data is available), probabilistic modeling can support retargeting workflows that require quick decisions.
Risk Management
Treat probabilistic output as directional: Use it to identify winners and losers quickly, not as the final source of truth.
Monitor model drift: Track changes in model performance over time (day-over-day variance, suspicious shifts after SDK or policy changes). If the model's signals change sharply, pause automation that depends on it.
Validate against SKAN cohorts later: When SKAdNetwork postbacks arrive (the more privacy-safe Apple postbacks), compare later SKAN cohorts and metrics to the earlier probabilistic readouts. Use differences to recalibrate the model or adjust confidence thresholds.
Limit actions that depend solely on probabilistic data: For big-budget or long-term decisions, wait for confirmed SKAN signals or run controlled experiments (incrementality) before scaling.
Probabilistic attribution is useful for speed and short-term optimization, but we plan to cross-check it with privacy-first signals and experiments. The most effective setups utilize probabilistic reads for agility and SKAN (or SSOT reconciled views) for final reporting and budget scaling.
What Single Source of Truth (SSOT) Brings to Unified Attribution
SSOT is a reconciliation layer typically built by an MMP that merges SKAN postbacks with device-level and modeled/MMP data, providing the business with a single reconciled dataset. This lets teams compare apples to apples without manual merging.
What SSOT does:
Removes duplicate install counts to prevent the same user from being counted twice across methods.
Lowers double-counting between SKAN and device-level matches.
Presents a unified set of metrics for reporting and BI exports, ensuring that product, creative, and paid teams use the exact numbers.
What SSOT is not:
Not a new way to attribute installs. It depends on the underlying methods (SKAN, ID matches, modeling) and inherits their limits (delays, thresholds, privacy blocking).
How Major MMPs Implement SSOT
Vendor | Short description of the approach |
AppsFlyer | SSOT in Data Locker/Reports: merges SKAN with ID-based signals and flags duplicates, ensuring that a user is counted only once. |
Branch | Unified Analytics: deduplicates SKAN and non-SKAN attribution, displaying combined totals in the dashboard. |
Singular | Unified Measurement reconciles SKAN and device-level data, offering options for extended cohort windows and modeled mapping. |
Kochava | SKAdNetwork Insights + Analytics Explorer: SKAN-first dashboards and detailed explorer views to reconcile SKAN with other metrics. |
Adjust | Side-by-side reporting: displays SKAN and device-level results adjacent, allowing teams to compare and reconcile manually or with Automate. |
Also Read: Top Mobile Measurement Partners (MMPs) in 2025
How to Interpret an SSOT Report
Fields to trust immediately (good starting point):
Deduplicated installs (the SSOT count where duplicates are removed) are suitable for cross-team reporting.
Cost and aggregated ROI metrics, if the MMP ingested cost and reconciled it with installs, are usable for top-line budget decisions.
Fields to treat as provisional (verify before making big changes):
Fine-grained campaign-level SKAN metrics for small-budget campaigns: SKAN has privacy thresholds and may not report for low-volume cells. Treat sparse campaign numbers cautiously.
Very recent performance (last 24–72 hours): SKAN postbacks can be delayed by Apple's timers and privacy windows; early signals may be incomplete.
Long-term LTV and revenue assigned to a single SKAN postback: It may be modeled or aggregated; check how the MMP maps conversion values and cohort windows.
Practical tip for marketers and marketing teams: treat the SSOT deduplicated totals as the canonical metric for reporting, but always inspect the raw SKAN and device-level tabs when questions arise (small campaigns, strange spikes, or suspected fraud).
Suggested watch: Learn how to build custom dashboards and unify ad data using Segwise's SSOT reporting tools in this step-by-step tutorial.
How to Pick the Best Approach
If fraud control is the top priority → favor SKAN-first workflows and SKAN-aware networks.
If the need is fast daily signals and there is a high scale → consider SSOT hybrid (SKAN + device-level + modeled) so daily optimization can run while still reconciling later.
If ATT opt-in rates are low for the audience → treat SKAN as the default data source for iOS reporting.
For remarketing to ATT-consented users → use device-level deterministic matches where allowed and consider probabilistic retargeting only where policy and privacy rules permit.
Choosing the Right Attribution Approach
Advertiser type | Campaign goal | Suggested approach |
High-scale UA | Direct response (install CPA) | SSOT hybrid (SKAN + device-level + modeled) |
High-scale UA | Brand/awareness | SKAN-first + aggregated reach |
Small/medium app | Low ATT opt-in | SKAN-only + probabilistic modeling |
Small/medium app | Moderate/high ATT opt-in | SSOT hybrid with device-level |
SSOT tools simplify reporting by merging SKAN and device-level signals, but they do not eliminate the limitations imposed by Apple's privacy rules and SKAN timers. Use the SSOT deduplicated totals for shared reporting, check the raw sources for edge cases, and select the stack that matches the campaign scale, ATT opt-in rates, and fraud tolerance.
Step-by-Step Guide to Running SKAN-First Campaigns
Below is a clear, practical SKAN playbook that fits the 2025 rules and Apple SKAdNetwork (SKAN 4+) behavior:
Prep (before launch)
Select a conversion-value (CV) mapping that associates early actions (such as signup and tutorial) with 0–2 day buckets and assigns revenue/retention to later buckets.
Register campaign IDs, connect ad partners, and set up MMP/SSOT reconciliation.
Launch & Early Monitoring
Use separate campaign IDs per creative group and start with a controlled budget.
Expect noisy, limited signals at first. Reconcile SKAN with SSOT and modeled reads.
Day-by-day
Day 1–5: initial, sparse postbacks; CPI and ROAS are unreliable.
Day 7–14: second postbacks arrive; directional patterns appear, but final clarity may wait for later windows.
When to Start Optimization
Begin meaningful adjustments after consistent signals from the second postback window (typically 7–14 days). Favor reversible moves: creative swaps, bid tweaks, and budget shifts.
What to Avoid
Pausing or killing campaigns on day 2–3.
Treating single-window reads as final.
Heavy optimization on low-volume campaigns (high chance of redacted/null data).
Practical Pro Tip:
Target ~100+ installs/day per campaign, or roughly $500–$1,000/day, where possible to reduce redaction. Map 0–2 day CV to early high-signal actions and use coarse buckets for later windows. Share the CV schema with partners.
Patience, planned CV mapping, and SSOT reconciliation give the clearest, privacy-first view of creative and ad performance in 2025.
What's Coming Next: SKAN 5.0, Incrementality & Privacy Trends
Apple's SKAdNetwork (SKAN) is moving beyond its earlier limits. The most notable updates in SKAN 5.0 include significantly faster postbacks (moving toward hours rather than multiple days), built-in support for incrementality testing, and native support for re-engagement and retargeting workflows, all aimed at providing teams with usable, privacy-safe measurement without raw user-level data.
A few practical notes about how this feels in practice:
Postback timing: Apple still enforces randomized timers for postbacks to protect privacy, but SKAN 5.0 reduces the typical wait and increases the chance of receiving earlier signals, meaning some campaign outcomes can be visible in hours rather than waiting several days. This change reduces latency for campaign decisions while keeping the privacy guardrails in place.
Incrementality and retargeting: SKAN 5.0 introduces features to help measure lift and support re-engagement campaigns within Apple's privacy model, enabling teams to test which creatives or audiences drive real incremental value without relying on device IDs. That shifts some experimentation from server-side probabilistic models into privacy-first, Apple-managed signals.
A note for Android:
Google's Privacy Sandbox for Android is following a similar path; measurement will be aggregated and privacy-first (event and aggregated reports, Attribution Reporting API, and Aggregation Service), reducing dependence on the advertising ID and pushing the ecosystem toward cohort/aggregate measurement instead of user-level tracking. This is an industry-wide change affecting cross-platform planning and creative testing strategies.
What this means for marketing teams:
Expect faster, but still privacy-limited, postbacks on iOS; plan experiments around aggregated windows rather than individual user paths.
Utilize SKAN's new incrementality and re-engagement tools to conduct controlled lift tests whenever possible, while maintaining probabilistic and MMP signals as complementary inputs.
Treat Android's Privacy Sandbox as a parallel, aggregated measurement system. Creative and audience tests should be designed to work with summed, cohort results rather than user-level attribution.
These updates narrow the gap between privacy and actionable insight: SKAN 5.0 and Google's Privacy Sandbox both push measurement toward faster, aggregated signals and built-in experimentability. Marketing teams should align their testing plans and reporting to leverage aggregated windows and the new SKAN capabilities, while also utilizing probabilistic models as a complementary approach, where feasible and legal.
Also Read: WWDC 2025 AdAttributionKit Update: 6 Major Improvements
Conclusion
Select the measurement that aligns with your reporting window and goals. Apple's SKAdNetwork (SKAN) offers privacy-preserving postbacks, with up to three timed postbacks that cover both short-term and mid-term conversion windows. It is the platform-approved attribution signal on iOS. Probabilistic models provide faster directional estimates but carry model uncertainty. Use a reconciled Single Source of Truth (SSOT) to combine SKAN, modeled, and device-level signals into a single report, enabling teams to work from the same numbers.
Collect creative IDs, campaign IDs, and server-side mappings before launch so SKAN postbacks can be linked to the correct creative when fields are available. Apple's privacy thresholds can suppress some SKAN fields, so accurate mappings and MMP integrations improve match rates.
Align cohort windows and conversion definitions across SKAN and modeled reports, such as 0 to 2 days, 3 to 7 days, and 8 to 35 days, and document these choices so that everyone uses the same metrics.
Segwise helps solve the creative performance gap in this setup. It's AI-driven creative tagging automatically breaks down images, videos, and audio into elements such as characters, hooks, or themes, then connects those tags to ad performance data across various networks. That capability can surface which creative features are tied to installs or revenue, track creative fatigue, and speed optimization when integrations and data feeds are set up correctly.
For teams ready to try this approach, Segwise offers a 14-day free trial to get started quickly.
Suggested watch: See this video to know how Segwise automatically connects creative elements to ad performance in this quick demo of AI-powered creative analytics.
FAQs
1. What is the main difference between SKAN and probabilistic attribution?
SKAN is Apple's privacy-first attribution API that sends limited, timed postbacks instead of user-level IDs. Probabilistic attribution utilizes device and contextual signals, along with statistical models, to estimate which ad is likely to have driven a conversion. Probabilistic methods can provide quicker, directional signals but carry model uncertainty and rely on assumptions.
2. How does SKAN handle privacy compared to other methods?
SKAN removes user identifiers and applies privacy thresholds and timers that prevent singling out individuals. Probabilistic approaches rely on aggregated or contextual signals and modeling; these approaches can be implemented in a privacy-compliant manner, but they provide estimates rather than direct device-level attributions.
3. What is SSOT, and how can it help my marketing team?
SSOT (Single Source of Truth) is a reconciled report that merges SKAN, device-level, and modeled data, allowing teams to share a single, clean dataset and avoid double-counting. This makes cross-team reporting, budgeting, and campaign comparisons simpler.
4. When should I use SKAN over probabilistic attribution?
Use SKAN when you need the platform-accepted, privacy-preserving signal on iOS, especially when ATT opt-in rates are low. Use probabilistic models as a supplement for faster directional insights or when broader signal coverage is needed. Treat modeled output as estimates and document the model assumptions.
5. How can an MMP with SSOT benefit my marketing efforts?
An MMP that provides an SSOT consolidates SKAN, device-level, and modeled data into one deduplicated report. This reduces reporting friction and makes it easier to align budgets and performance decisions across teams.
