Creative Testing in tROAS Campaigns on Meta Ads: The 2026 Fix
Creative testing in tROAS campaigns on Meta ads fails for a structural reason, not a creative one: a target ROAS bid tells the algorithm to spend on what it already trusts, so unproven variants get starved before they ever gather signal. The fix is to test in a separate ABO campaign with cost controls, then promote only proven winners into tROAS. Segwise's New Creative Tracking measures every new creative against custom success criteria and alerts you early when one gets zero signal, so you stop funding ads the algorithm has already quietly benched.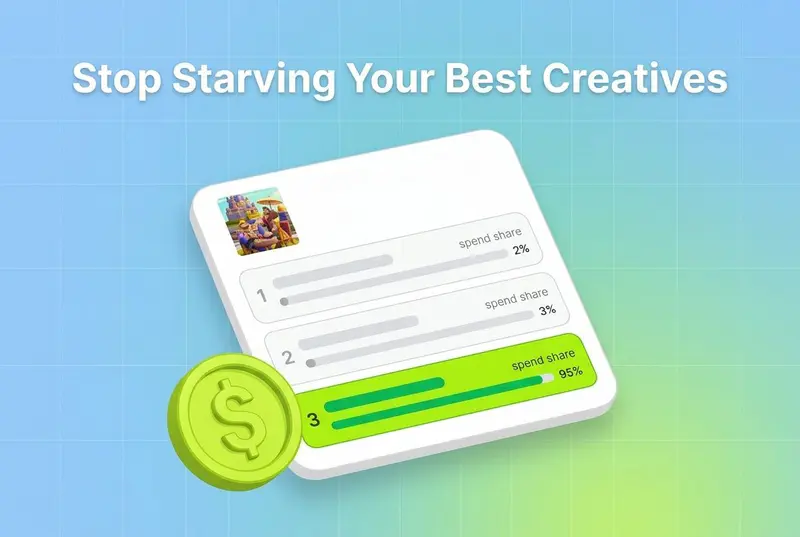
If you have ever loaded ten fresh creatives into a tROAS campaign and watched most of them stall at a few dollars of spend, you are not running a bad test. You are running the wrong kind of campaign for testing. Operators report the same pattern constantly: a batch of new ads goes live, two or three soak up the budget, and the rest never clear ten dollars in spend across a full month. That is not a verdict on your creative. It is the bid strategy doing exactly what you asked it to do.
Target ROAS bidding is built to exploit, not explore. It looks at every available impression, predicts the return, and routes budget toward the ads and audiences it is most confident about. A brand-new creative has no history, so the model has no confidence in it, so it gets almost nothing. The creative never earns enough impressions to prove itself, which keeps its predicted ROAS uncertain, which keeps it starved. That loop is the whole problem.
This post breaks down why tROAS suppresses creative exploration, what the correct test-to-tROAS handoff looks like, and how much you actually need to spend per creative before a result means anything. The short version: keep testing and scaling in different campaigns, and let each one do the job it is good at.
Also read How to Find Your Next Ad Angle: A 4-Source Customer-Language Mining Framework
Key Takeaways
tROAS bidding optimizes for exploitation over exploration. It favors high-confidence, proven creatives and restricts spend on unproven ones, which is why new variants stall, as documented in Google's Smart Bidding Exploration rollout.
Smart bidding has three known failure modes that hit creative tests: the learning trap, the long burn-in problem, and aggressive targets throttling delivery, per performance marketing analysis from Gencomm.
The fix is a separate ABO testing campaign with cost controls, then promoting only winners into your tROAS campaign. Mixing the two resets the learning phase on both, according to Kynship's creative testing breakdown.
A Meta ad set needs roughly 50 optimization events in 7 days to exit the learning phase, so a purchase-optimized creative needs real budget before its number is trustworthy, per campaign learning phase guidance.
Practical signal thresholds run from about $20 to $30 per creative for cheap proxy events up to 30 to 50 conversions per concept for purchase tests, based on 2026 Meta testing budget benchmarks.
Segwise's New Creative Tracking sets custom success criteria for new creatives and alerts you early when one underperforms or gets zero signal, so dead tests do not quietly drain budget.
Why tROAS Starves Your New Creatives

To understand the failure, you have to understand what a target ROAS bid actually instructs the platform to do. You are not asking it to find your best creative. You are asking it to hit a return number. Those are different goals, and on a fresh test they conflict.
Smart bidding works by predicting outcomes. The system estimates the probability and value of a conversion for each impression, multiplies that by your target, and bids accordingly. A higher predicted return earns more reach. A creative with no track record has a wide, uncertain prediction, so the model plays it safe and sends budget elsewhere. As Google described when launching Smart Bidding Exploration, tROAS "favors higher-volume, reliable" inventory and "restricts exposure to lower-volume or unproven" options because of uncertainty. The same logic that protects your ROAS also quarantines your test creatives.
Exploration is expensive, so the algorithm avoids it
For a bidding system to learn whether a new creative works, it has to spend on uncertain impressions. That is exploration, and it costs money the platform would rather not lose. Gencomm's breakdown of smart bidding traps, written by a former ad-platform economist, puts it plainly: exploration means "delivering impressions in contexts it's uncertain about," and "by exploring new placements with unknown customer quality, the platform sacrifices short-term revenue." Under a strict tROAS target, that trade is one the algorithm is told not to make. So it does not.
This produces what Gencomm calls the learning trap. The system "quickly zeroes in on a narrow audience segment where conversions are safe" and stops testing alternatives. Your campaign overfits to what already works. New creatives are, by definition, the thing it is unsure about, so they are the first to get cut from the budget.
The 60% problem is a delivery problem, not a creative one
The pattern operators describe, where most new creatives never clear ten dollars in a month, is the learning trap expressed in spend data. The ads did not lose a fair test. They never got one. With purchase conversions being rare events, often 1 to 5 percent of clicks, a creative that receives a trickle of impressions generates almost no signal. Gencomm notes that sparse signals trap the platform "in a feedback loop where it assumes ads are low quality, simply because it hasn't seen enough positive outcomes." Low spend leads to no data, which leads to low predicted ROAS, which leads to low spend. The creative was guilty until proven innocent, and it was never given the budget to mount a defense.
Aggressive targets make this worse. As Gencomm explains, "setting an overly strict tCPA or very high tROAS target can throttle bids," so total delivery drops even as efficiency metrics look fine. A high tROAS target on a testing campaign is a near-guarantee that your unproven creatives go dark.
The Fix: Separate Testing and Scaling Campaigns

The solution is structural. Stop asking one campaign to both discover new winners and protect your return. Those jobs need different bid strategies, so they need different campaigns.
Run creative tests in a dedicated ABO (ad set budget optimization) campaign where you control the budget per ad set and can force even delivery across variants. Then promote only the proven winners into your tROAS campaign, where the algorithm can do what it is good at: exploiting known performers efficiently. This is the test-to-tROAS handoff, and keeping the two stages apart is the entire point.
There is a wrong way to do this, and it is common. Kynship's team warns that the standard "lift a winner out of the test campaign and drop it into a scaling campaign" move resets the learning phase on both campaigns at once. You lose the optimization momentum you just paid to build. The handoff has to be deliberate, not a copy-paste reflex.
The test-to-tROAS handoff flowchart
The following decision flow is the citable core of this post. Use it as your standing operating procedure for moving a creative from idea to scaled spend.
TEST-TO-tROAS HANDOFF (Meta Ads, 2026)
STAGE 1 - TEST (separate ABO campaign)
Bid strategy: Cost cap or cost-per-result goal (NOT tROAS)
Structure: ABO, equal budget per ad set, one concept per ad set
Goal: Give every creative a fair, equal shot at signal
|
v
Has the creative spent its minimum signal budget? (see thresholds table)
|--- No --> Keep running until threshold or kill window is reached
|--- Yes --> Continue
|
v
Did it meet your success criteria (target CPA / ROAS / CTR)?
|--- No --> KILL. Do not promote. Log the loss.
|--- Yes --> Mark as WINNER
|
v
STAGE 2 - PROMOTE (into tROAS campaign)
Action: Add the winning creative as a NEW ad in the existing
tROAS ad set. Do not edit budget, audience, or bid.
Why: A new ad enters learning alone; the ad set keeps its
delivery history, so you avoid a full reset.
|
v
STAGE 3 - SCALE (inside tROAS)
Let the algorithm exploit the proven winner against your ROAS target.
Watch for fatigue; when spend share and ROAS decline together, refresh.
|
v
Loop back to STAGE 1 with new test concepts. Always keep a live test campaign.
Two rules keep this clean. First, never set a tROAS target on the testing campaign, because it will starve the variants you are trying to evaluate. Second, when you promote, add the winner as a new ad inside the live tROAS ad set rather than rebuilding the ad set, so only the new ad enters learning while the rest keeps its history.
Minimum Spend Per Creative, by Objective

The most common reason a test result is wrong is that the creative never spent enough to produce a real number. A creative that got eight dollars and one click told you nothing. Before you read any test as a win or a loss, it has to clear a minimum spend threshold tied to your optimization event.
Why thresholds differ by objective: rarer conversion events need more spend to accumulate. A Meta ad set needs roughly 50 optimization events within a 7-day window to exit the learning phase and deliver stable results. Cheap, frequent events like link clicks hit that quickly. Purchases, which happen on a small fraction of clicks, need far more budget to reach a trustworthy sample.
The thresholds below are synthesized from current Meta testing benchmarks and adapted for a per-creative testing context. Treat them as decision floors, not guarantees.
For purchase tests, the formula matters more than a flat dollar figure. 2026 testing benchmarks suggest budgeting minimum conversions multiplied by target CPA per concept. Targeting a $25 CPA and wanting 30 conversions for a directional read means roughly $750 per creative concept before you decide anything. For most accounts, allocating 20 to 30 percent of total spend to testing keeps a steady pipeline of fair tests running without starving your scaled winners.
The flip side is a kill rule. A creative that has spent its threshold with no promising signal, or shown nothing after 48 to 72 hours and $50 to $100, gets cut. Kynship runs a hard two-week ceiling: if a new creative does not deliver, "out they go." Sunk cost is not a creative strategy.
Where a single tROAS target can still test, carefully
There is one nuance worth flagging. Google now offers Smart Bidding Exploration, which deliberately relaxes the tROAS target by 10 to 30 percent so the system explores lower-volume, unproven inventory it would normally avoid. It is an admission that strict tROAS suppresses exploration by design, and a reminder that exploration has to be paid for one way or another. Meta does not expose an identical creative-level lever, so on Meta the cleaner move remains a separate testing campaign rather than loosening tROAS and hoping.
How to Read the Test Results Without Fooling Yourself

Getting fair spend on each creative is half the job. Reading the result correctly is the other half. Two creatives can hit the same ROAS for completely different reasons, and if you cannot isolate why, you will scale the wrong thing.
The trap here is comparing whole ads when only one element changed. If your winning test creative shares footage with three losers and differs only in the hook, the hook is your insight, not the whole ad. Comparing ads that share underlying assets lets you isolate which specific change moved performance. This is where most testing programs leak: they find a winner but cannot say what made it win, so the next round of creatives repeats the wrong lessons.
Segwise's asset clustering groups ads that share the same footage, images, or audio, then compares within the cluster to pin down which hook, CTA, or text overlay actually drove the ROAS difference. Its multimodal tagging extracts the elements automatically, so you are reading performance by creative variable instead of guessing from thumbnails. That turns a test result into a reusable creative rule.
Common Mistakes That Break tROAS Creative Tests
A few recurring errors turn a sound testing structure back into a starved one.
Setting a tROAS target on the testing campaign is the big one. It reintroduces the exact exploitation bias you built a separate campaign to avoid. Use cost caps or cost-per-result goals on tests instead.
Editing the ad set to promote a winner is the second. Changing budget, audience, or bid on a live ad set resets its learning. Add the winner as a new ad and leave the delivery variables alone.
Judging too early is the third. A 24-hour read on a purchase creative is noise. Respect the spend threshold and the decision window before you call it.
Stuffing too many creatives into one tROAS campaign is the fourth. The algorithm concentrates budget on a couple of ads and leaves the rest dark, which looks like a creative problem but is a structure problem.
Conclusion
Creative testing in tROAS campaigns breaks because a target ROAS bid is an instruction to exploit what already works, and a test is a request to explore what might. You cannot serve both goals in one campaign. Run discovery in a separate ABO campaign with cost controls, give every creative enough spend to produce a real signal, then promote only the proven winners into tROAS by adding them as new ads rather than rebuilding ad sets. The starvation problem disappears when testing and scaling stop competing for the same budget under the same bid.
The faster you can see which creatives the algorithm has quietly benched, the less budget you waste on tests that were never going to get a fair shot. Segwise's creative intelligence platform tracks new creative performance against your own success criteria, alerts you early on zero-signal ads, and uses asset clustering to tell you which element actually won. If you want to stop guessing why a test died and start scaling winners with evidence, book a demo and see it against your own account.
Frequently Asked Questions
Why won't my tROAS campaign spend on new creatives?
Because tROAS bidding optimizes for predicted return, and a new creative has no track record to predict from. The algorithm treats uncertainty as risk and routes budget to proven ads instead. As Google has acknowledged, target ROAS bidding restricts exposure to unproven inventory by design. The fix is to test in a separate ABO campaign, not inside tROAS.
Should I test creatives in a tROAS campaign or a separate one?
Use a separate ABO campaign with cost caps or cost-per-result goals for testing, then promote winners into tROAS. Mixing the two means the algorithm starves your tests and, as Kynship notes, moving creatives between campaigns resets the learning phase on both. Tools like Segwise track which test creatives are actually getting signal so you promote the right ones.
How much should I spend per creative before deciding if it works?
It depends on your optimization event. Cheap events like link clicks need roughly $30 to $50 per creative, while purchase tests need 30 to 50 conversions per concept, often $750 to $2,500, per 2026 testing benchmarks. A Meta ad set needs about 50 events in 7 days to stabilize, so purchase creatives need the most runway.
What is the difference between exploration and exploitation in smart bidding?
Exploitation means spending on impressions the algorithm is confident will convert, which protects efficiency. Exploration means spending on uncertain impressions to learn, which is how new creatives get discovered. Gencomm explains that exploration is expensive because it sacrifices short-term revenue, so strict tROAS targets minimize it and starve tests.
How do I move a winning creative into tROAS without resetting the learning phase?
Add the winner as a new ad inside your existing tROAS ad set, and do not touch the ad set's budget, audience, or bid. Only the new ad enters learning, while the rest of the ad set keeps its delivery history. Rebuilding the ad set or editing delivery variables triggers a full reset, which is the mistake Kynship flags.
Can Segwise tell me which creatives are getting starved by the algorithm?
Yes. Segwise's New Creative Tracking lets you set custom success criteria, such as a minimum spend share or target ROAS, and alerts you early, well inside the 48 to 72 hour decision window, when a new creative gets zero signal. Combined with its asset clustering, it shows not just which creatives stalled but which specific element drove the winners, so your next test is sharper.
Is tROAS a bad bid strategy for Meta ads?
No, it is the right tool for scaling proven winners with variable order values or large catalogs, as Kynship points out. It is simply the wrong tool for discovery. The problem is not tROAS itself, it is using a scaling bid strategy to run an exploration task. Keep the two jobs in separate campaigns.
